This post originally appeared in two parts on my personal blog at flxsql.com and has been reposted here by request.
A bit over a year ago, I blogged about my experience migrating a test SQL Server instance from a VM to a physical machine with a little help from my friends. That migration went well and the instance has been running trouble-free ever since. But it’s small potatoes. A modest instance, it’s only about 5% the size of production. With SQL Server 2008R2’s EOL looming, it was time to migrate production to SQL Server 2016. It’s a pretty beefy setup:
- 2-node Failover Clustered Instance
- 16 cores
- 768GB RAM
- 4 TB of storage
- Over 8000 databases
The Challenge
How do you move eight thousand databases in a reasonable amount of time?
I spent about an hour and a half one morning hashing ideas out w/ folks in the dbatools Slack channel, plus several conversations in the office and with our hosting provider.
Start-DbaMigration? I love that function but it’s single-threaded and we just don’t have time to backup & restore that many databases that way.- Backup & restore? Multi-threaded, our daily full backups take over 3 hours to run. Double that to do a backup & restore.
- Detach & reattach? We’ll need either double the storage and eat the time copying the data, or risk the time required to restore from backup if we have to revert.
- Log shipping, mirroring, replication? Again, double the storage, and we have so many databases that it’s just not feasible.
- In-place upgrade? Not supported by our hosting provider, and there’s not much of a safety net.
Ultimately the team settled on a variation of the detach & reattach.
- Install SQL Server 2016 on new physical servers with “dummy” drives (so that paths could be set during install)
- Shut down SQL Server 2008R2
- Take a SAN snapshot
- Move the LUN to the new server
- Attach the databases
This is the fastest way for us to move the data, and the snapshot provides a way back if we have to revert. We have backups as well, but those are the reserve parachute – the snapshot is the primary. This process is easiest if the paths for the data and log files remain the same. But that didn’t happen here. On the old instance, both data and logs were dumped in the same directory. The new instance has separate data and log directories. And it’s a new drive letter to boot.
OK, so how do you attach eight thousand databases and relocate their files in a reasonable amount of time?
It’s dbatools to the rescue, with Mount-DbaDatabase being the star of the show. Not only does it attach databases for you, you can use it to relocate and rename the files as well. But that’s really one of the last steps. We have setup to do first.
Preparation
Basics
Once the servers were turned over to us, the DBA basics had to get set up. I configured a few trace flags for the instance with Set-DbaStartupParameter -Traceflags 3226,4199,7412,460.
| Trace Flag | Purpose |
|---|---|
| 460 | Enable detailed String or Binary Data would be truncated error message in a future Cumulative Update |
| 3226 | Suppress successful backup messages in the error log |
| 4199 | Enable query optimizer fixes in CUs and hotfixes |
| 7412 | Enable lightweight execution statistics profiling |
Since publishing the original post, I’ve received a couple questions about the use of TF4199. With the database-scoped option QUERY_OPTIMIZER_HOTFIXES this isn’t absolutely necessary to get post-RTM hotfixes for the optimizer. Pedro Lopes (blog|twitter) recommended in his Summit 2018 to enable it globally, and he confirmed that in an email exchange with Andy Galbraith (blog|twitter) that Andy wrote up on his blog. Pam Lahoud (twitter) wrote about the topic in a recent post as well.
I did use Start-DbaMigration but excluded Databases, Logins, AgentServer, ExtendedEvents (the last because we don’t use XE on the old instance anyway; this avoided any warnings or errors related to it). Excluding databases makes sense given what I wrote above, but why logins and Agent jobs?
The source instance is several years old and has built up a lot of cruft; this migration was a good chance to clear that out. All disabled logins and jobs were scripted out and saved, and only the active items migrated. But that also meant I couldn’t use Copy-DbaAgentServer because it doesn’t filter jobs out; a few extra steps were necessary. For reasons I don’t understand, Start-DbaMigration copied our database mail and Linked Server setups faithfully, with one exception – the passwords.
We were able to fix that up easily enough but I found it strange that of all things, the passwords weren’t copied properly. Especially since I’ve done this successfully with dbatools in the past.
Moving logins
Although I only wanted to migrate the currently-active logins, I wanted the ability to re-create any disabled logins just in case, so I needed to extract the create scripts for them. I achieved this via Get-DbaLogin, Export-DbaLogin, and Copy-DbaLogin:
Moving Agent jobs
I had the same need for Agent jobs, and achieved it similarly. However, because I excluded the AgentServer from Start-DbaMigration, I had to peek into that function to find out all the other things it copies before copying the jobs. I also wanted to leave the jobs disabled on the new server so they didn’t run before we were ready to test & monitor them in a more controlled way.
Maintenance & Monitoring
When that was complete, we updated the community tools that are installed in system databases
- Brent Ozar’s First Responder Kit –
Install-DbaFirstResponderKit-database master -force - Adam Machanic’s
sp_whoisactive–Install-DbaWhoIsActive-database master - Ola Hallengren’s Maintenance Solution –
Install-DbaMaintenanceSolution-database master
By default, this function doesn’t install Agent jobs, which is fine here. I already copied the Agent jobs over, but I wanted the latest & greatest versions of the backup and index maintenance stored procedures that they call.
We use MinionWare’s Minion CheckDB but didn’t need do a separate installation or migration. With the exception of the Agent jobs, everything is self-contained in a single database. The Agent jobs were copied above, and the database came over with all the others.
Ready to Go
With the above complete, there wasn’t much left to do aside from doing some small-scale testing of the database attachment process and validating system operations (database mail, backups, CheckDB, etc.). ## Final Prep We completed our nightly backups as usual on Friday night, so when I arrived Saturday I kicked off a final differential backup to catch any overnight changes. We’ve multi-threaded Ola’s backup script by creating multiple jobs and I started them all at once with (of course) PowerShell.
Get-DbaAgentJob -SqlInstance $OldInstance | Where-Object {$_.name -like 'user database backups - diff*'} | ForEach-Object {$_.Start()}
I estimated that the diff backups would take about 90 minutes based on a couple test runs; they took 100 minutes (not too shabby!). While that ran, I re-exported the Agent jobs just to be sure I had everything captured there. I also copied a few databases to another 2008R2 instance in case they were needed for debugging purposes. The very last step was to extract a listing of all our databases and the full paths to the physical data and log files, then split them into ten files.
The method I used to attach the databases wasn’t scalable to running it for all eight thousand databases at once and this let me control the batch sizes easily.
The resulting CSV file gave me each database file, the type of file (data or log), and the database name itself.
| database_id | name | FileType | physical_name |
|---|---|---|---|
| 7 | MyDatabase | ROWS | S:\Very\Long\Path\MyDatabase.mdf |
| 7 | MyDatabase | LOG | S:\Very\Long\Path\MyDatabase_1.ldf |
Time to Move
With all of our pre-migration work complete, we shut down the SQL Server 2008R2 instance. Then we turned things over to the folks in the datacenter to detach the storage LUN, take the snapshot, and attach the LUN to the new instance. When their work was complete, they passed the baton back to me to move the files around and attach the databases.
Attaching the Databases
Before reading this section, I suggest you read two other recent posts, PowerShell Multithreading with PoshRSJob and Thread-safe PowerShell Logging with PSFramework, as they’ll provide the background for how some of this was done.
I created my own function as a wrapper for Mount-DbaDatabase from dbatools, adding the extra features I needed (or thought I needed):
- Logging
- Multi-threading
- Logically renaming the files
- Setting the database owner appropriately
- Rebuilding indexes
- Upgrading the
CompatibilityLevel
In practice, I only used the first four in the initial attachment of the databases for the upgrade. Example execution:
Get-MountProgress is a variation on one of the functions in my multithreading post above, which let me keep tabs on the progress as the function ran. I ran the above code ten (well, eleven) times, once for each “batch” of 10% of the databases. The first group ran great! Only about 6 minutes to attach the databases. The next batch was 10 minutes. Then 16. And then, and then, and then…
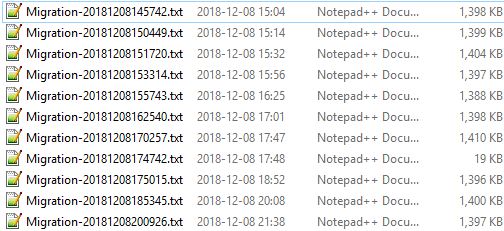
From the timestamps on the log files, you can see that each batch took progressively longer and longer. It was agonizing once we got past the 5th group. I have observed that SMO’s enumeration when connecting to a database instance can be lengthy with large numbers of databases on the instance, which would correlate to what I observed; the more databases I have, the longer it takes. But I can’t completely attribute the slowdown to this.
Partway through, we shifted gears a bit and I ran a special group of databases which hadn’t yet been attached but the QA team needed for their testing. This let them get rolling on their test plans without waiting longer.
Memory consumption for powershell.exe was very high as well, and kept growing with each batch. After the 3rd batch, I decided I needed to exit PowerShell after each one and restart it just to keep that from getting out of hand. I’m not sure what happened there; maybe a runspace memory leak?
I had estimated attaching the databases would take about one hour. It took over six and a half. There was no one more upset over this than me. On the up side, the logs showed nothing but success.
Validation
Once we realized that attaching the databases was going to run longer than expected, our developers and QA team pivoted to testing what they could with the databases we had attached early on. In hindsight, I should have asked them which databases they needed for their test plans and attached those right away, so that they could test while ther remainder of the databases were running. But, great news! They didn’t find any issues that could be directly attributed to how we did the migration of the data.
I re-ran my earlier PowerShell to fetch the databases and their files from sys.databases against the new instance and compared to the original; everything matched! Confirmation that all of the databases were attached.
Final Steps
We missed the estimated time for our go/no-go decision by five minutes. With the number of moving parts, databases in play, unexpected delays, and amount of testing we had to do, that’s pretty good! My colleague and I had some additional work we needed to take care of after the team declared the migration a success. Agent jobs needed to be enabled, overnight job startups monitored, things like that. We called it a day after about 14 hours in the office.
The next day, we had some more tasks to complete. Per a blog post by Erin Stellato (blog|twitter) back in May, because we upgraded from 2008R2 to 2016, an index rebuild was advisable for all our nonclustered indexes. I did this via Red Gate Multi Script and some dynamic SQL instead of PowerShell this time, looping through all the NC indexes in each database and running ALTER INDEX REBUILD.
Aftermath
Our first few days post-upgrade didn’t go well. CPU usage and response times were terrible and after checking over everything for days on end, we finally tracked it back to a piece of code that was still looking for the old SQL Server 2008R2 instance. Once that was fixed, everything came back to normal.
A few days post-migration, we did have one problem caused by a change in SQL Server 2016. It seems that SQL Server got a little stricter about doing subtraction of integers from time types (instead of using dateadd()). Correcting it was pretty easy as it was limited to a couple stored procedures which are used in a limited capacity.
Lessons Learned
It’s not a good project without some solid lessons learned! What could we have done to make migration day easier?
- Work out which databases need to be available for performing post-upgrade checks and attach those first
- Work in smaller batches (not sure how much this would have helped)
- Have a test environment that’s as close as possible to production in all aspects
Conclusion
I suppose you’re expecting me to say something profound here. The most surprising thing to me about this migration is that there were no major surprises. Aside from one portion taking longer than anticipated and those two small pieces of code, everything went to plan. All in all, our migration is a success and after working out a few glitches in the week or two after, things have been running well. We’re on a modern release now, and looking forward to taking advantage of the new features available to us now.
- Andy Levy, flxsql.com
Andy, great post and scripts. I’m new to powershell, but was curious about your approach to the common and complex migration challenge. In your scenario, you mentioned some apps were still pointing to the old server. Did you have to create a new DNS for the destination server instead of changing the IP for alias?
Yes, the new server was set up as a completely new box. New hostname, new IP, everything. The old server was not taken offline/powered off/removed from the rack for about 3 weeks after the migration was completed. The issue with the app is that it had a connection string embedded in the code which we were not aware of.
In some respects it would have been easier if we could have kept the same hostname and IP, but that was not an option for this project.
Over EIGHT THOUSAND databases on one server? Wow. I can imagine the startup time…well, I can imagine a lot of things on that box… anyway, Great read and good job with the migration!
Andy, great job. I am thinking of applying your method to move around 1500 databases to new server. In your description above you mentioned about Get-MountProgress. Do you have the script for that?
Thanks! I don’t have the code for that function anymore, but you can see something close to it in the post on my blog where I demonstrated PoshRSJob. That is available at https://flxsql.com/powershell-multithreading-with-poshrsjob/ – scroll down to “Bonus Round”.